
Keep AI uptime and costs controlled
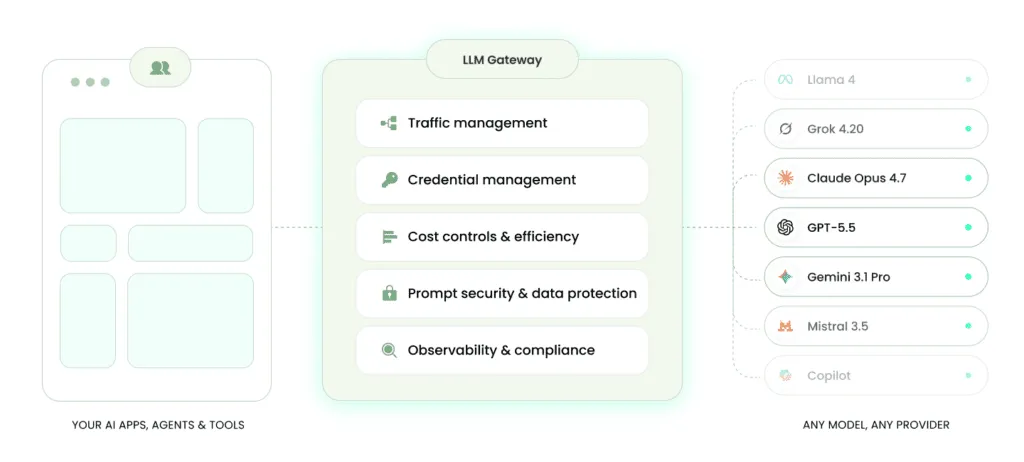
LLM gateway for production-ready AI
01
Universal endpoint
02
Model routing
03
Credential management
04
Cost control
05
Full visibility
06
Prompt security

Run reliable AI apps
Uptime that doesn’t depend on any one provider.
- Routing: Switch to a backup model if a provider fails or hits rate limits without code changes.
- Health checks: Pull degraded providers from rotation in real time and reinstate them when they recover.
- Circuit breaking: Stop sending traffic to failing providers before errors cascade.
Protect provider keys
Create virtual keys and manage changes from one place.
- Issue per app or agent: Generate a virtual key for every team, app, or agent that needs model access.
- Rotate without code changes: Cycle, revoke, or update keys from the gateway without changing code.
- Monitor and control usage: Track every call made with every key, and revoke access the moment it’s no longer needed.

Control AI costs
Predictable AI spend, no surprise overages.
- Per-team, per-user, per-model budgets: Set independent spend caps that match how teams operate.
- Rate limiting: Throttle by request count and traffic volume to prevent runaway scripts.
- Budget enforcement: Enforce limits at the gateway and avoid surprise invoices.

Monitor AI traffic
Track model performance, routing, and spend.
- Real-time dashboard: Track every call by latency, tokens, model, and status in one view.
- Audit history: See routing decisions and error codes call by call.
- Log streaming and export: Pipe activity into your existing audit and observability stack.
Built for enterprise environments

SaaS
Fully managed deployment for fast setup and ongoing updates.
Private Cloud
Deployed in your cloud environment to meet security and compliance requirements.
On-Prem
Run entirely within your infrastructure for maximum control and data residency.
Frequently asked questions
What is an LLM gateway and what does it do?
An LLM gateway is a governance and enforcement layer that sits between your applications and model providers, giving teams centralized control over model access, cost, routing, and data protection.
The Barndoor LLM Gateway handles request routing, virtual key management, budget enforcement, and inline prompt and response inspection — all configured once and enforced consistently across every model call. This is the foundational layer for enterprise AI governance at scale.
How do you manage LLM costs and model access across multiple teams?
The Barndoor LLM Gateway lets you assign separate virtual keys, spend limits, and model permissions per team — mapped directly to your identity provider groups so access stays in sync as your org changes.
Each team operates within its own policy scope: the models they can call, the budget they can consume, and the providers they can reach are all enforced at the gateway level before a request is ever sent.
How does an LLM gateway handle model routing, provider support, and failover?
The Barndoor LLM Gateway works with all major model providers — including OpenAI, Anthropic, and Google — and supports deterministic routing rules, waterfall sequencing, and automatic circuit breaking if a provider goes down.
You can define which models are permitted, sequence providers by priority, and configure fallback behavior centrally. Adding a new provider is a configuration change, not an integration project.
How does an LLM gateway protect sensitive data and PII in prompts and responses?
The Barndoor LLM Gateway runs Barndoor data protection inline on every prompt and every response, intercepting sensitive data — PII, credentials, confidential content — before it reaches the model or is returned to the user.
When a policy fires, admins choose exactly how the data is handled. Tokenize replaces a value with a placeholder for the model call, then restores the original on the way back — the LLM never sees the real value but the user gets what they need. Mask keeps a useful suffix like the last four digits of an SSN. Obfuscate substitutes a structurally similar synthetic value so the model processes a realistic prompt without real data. Redact replaces the value with a [REDACTED] marker visible to both model and user. Omit removes it silently with no marker. Policies can also be set to alert only — notifying security teams without modifying the request — or allow the request through unchanged.
Every policy decision is logged with a full audit trail of what was detected, which rule fired, and how the data was handled.
What observability does an LLM gateway provide?
The Barndoor LLM Gateway gives platform engineers and developers a unified view of everything flowing through their AI infrastructure — request volume, token consumption, latency, cost, and model usage, broken down by team or virtual key.
Rather than piecing together data from individual provider dashboards, every request is captured in a single audit trail. That gives engineering leads and CTOs the visibility they need to monitor system health, track spend against budgets, and demonstrate responsible AI usage to stakeholders.
Can you integrate third-party security tools with an LLM gateway?
Yes — the data protection capabilities in the Barndoor LLM Gateway are modular, so existing security tooling can be layered in at the gateway level rather than replaced.
Organizations that have standardized on enterprise data loss prevention (DLP) vendors can position those tools alongside Barndoor data protection’s native inspection, while still centralizing routing, access controls, and audit trails through the Barndoor platform.